Resolving Scipy.Norm.Pdf’s Over 1 Issue: Recovery Guide By adminPosted on July 7, 2023 Are you tired of getting the dreaded Scipy.Norm.Pdf’s Over 1 error message when attempting to analyze your data? Don’t worry – you’re not alone. Countless researchers and data scientists have struggled with this problem and found it to be a frustrating roadblock. However, there is hope. By utilizing proven recovery techniques, you can overcome this issue and return to smooth analysis in no time. This guide will walk you through the steps necessary to resolve the Scipy.Norm.Pdf’s Over 1 problem. With clear explanations and helpful examples, you’ll gain a strong understanding of what causes this error in the first place and what you can do to mitigate its impact on your research. Whether you’re a seasoned data analyst or a beginner just starting out, the strategies in this guide will help you take your work to the next level. So why wait? Don’t let the Scipy.Norm.Pdf’s Over 1 error hold you back any longer. With the guidance and tools offered in this recovery guide, you can quickly get back on track and start making meaningful insights from your data once again. So grab a cup of coffee, settle in, and let’s get started solving this common issue together. “Why Does Scipy.Norm.Pdf Sometimes Give Pdf > 1? How To Correct It?” ~ bbaz Resolving Scipy.Norm.Pdf’s Over 1 Issue: Recovery Guide Introduction Scipy is a robust library for scientific computing in Python. The scipy.stats module provides tools for statistical analysis and calculating probability distributions. One of these distributions is the normal distribution, which is commonly used in many fields. However, sometimes the Scipy.norm.pdf function may return values over 1, causing confusion and errors. This article aims to clarify the issue and provide a recovery guide. Understanding the Issue To understand why Scipy.norm.pdf can return values over 1, we should first understand what this function does. Scipy.norm.pdf calculates the probability density function (PDF) of the normal distribution at a given point. The PDF represents the relative likelihood that a random variable takes on a certain value within a given range. The Normal Distribution The normal distribution is a continuous probability distribution that describes a large number of natural phenomena. It is characterized by two parameters: the mean (μ) and the standard deviation (σ). The PDF of the normal distribution has a bell-shaped curve with its peak at the mean. The PDF Formula The formula for the normal distribution PDF is: Why Values Over 1? The normal distribution PDF is not bounded in any range, meaning that its maximum value is not fixed. The height of the curve at any point depends on the values of μ and σ, but it can theoretically be any positive number. Therefore, it is possible for Scipy.norm.pdf to return values over 1, especially for large values of σ. Recovery Guide If you encounter values over 1 when using Scipy.norm.pdf, don’t panic! There are several ways to recover from this issue: Normalize the Distribution One way to recover from this issue is to normalize the distribution so that the PDF values are scaled between 0 and 1. This can be done by dividing the PDF by its integral over the entire domain, which ensures that the total probability of the distribution sums up to 1. Here’s an example code snippet: Original Code Modified Code pdf = scipy.stats.norm.pdf(x, mu, sigma) pdf = scipy.stats.norm.pdf(x, mu, sigma) / scipy.integrate.simps(scipy.stats.norm.pdf(x, mu, sigma), x) Use Scipy.norm.cdf Instead Another option is to use the cumulative distribution function (CDF) of the normal distribution instead. The CDF represents the probability that a random variable takes on a value less than or equal to a given point. Since the CDF is always between 0 and 1, this avoids the issue of PDF values over 1. Here’s an example code snippet: Original Code Modified Code pdf = scipy.stats.norm.pdf(x, mu, sigma) cdf = scipy.stats.norm.cdf(x, mu, sigma) Clip the Values A third option is to clip the PDF values above 1 to 1. This may not be ideal in some cases, but it can be a quick and dirty solution for cases where the PDF values are only slightly over 1. Here’s an example code snippet: Original Code Modified Code pdf = scipy.stats.norm.pdf(x, mu, sigma) pdf = np.clip(scipy.stats.norm.pdf(x, mu, sigma), 0, 1) Conclusion In conclusion, Scipy.norm.pdf can return values over 1 due to the unbounded nature of the normal distribution PDF. However, this issue can be easily resolved using normalization, the CDF, or value clipping. It’s important to understand the underlying concepts of the normal distribution and probability density functions to properly handle such issues. Dear valued blog visitors, As we come to the end of this article on resolving Scipy.Norm.Pdf’s over 1 issue, we hope that you have found the information provided to be helpful and informative. It can be frustrating when you encounter technical difficulties with a crucial tool such as Scipy, which is why we’ve put together this recovery guide to assist you in handling this specific issue. Remember, we understand that this issue may seem complex and difficult to resolve, but don’t hesitate to reach out for help. You can get in touch with the Scipy community or consult their documentation to find even more resources that can be of use to you. In addition, stay up-to-date with the latest version updates to mitigate potential issues that may arise in the future. We hope that you’ve enjoyed reading this article, and that it has aided you in resolving any issues you’ve encountered while utilizing Scipy.Norm.Pdf’s. Thank you for visiting our blog and we look forward to providing even more educational content in the near future. Are you having issues with Scipy.Norm.Pdf’s over 1? Don’t worry, we’ve got you covered! Here are some commonly asked questions about resolving this issue: What causes Scipy.Norm.Pdf’s over 1? Scipy.Norm.Pdf’s over 1 can occur when the probability density function (PDF) is not properly normalized. This means that the area under the curve of the PDF is greater than 1, which is not possible since probabilities cannot exceed 1. How can I fix Scipy.Norm.Pdf’s over 1? To fix Scipy.Norm.Pdf’s over 1, you need to normalize the PDF. This can be done by dividing the PDF by its integral, which will ensure that the area under the curve is equal to 1. Can I still use Scipy.Norm.Pdf’s if they are over 1? No, you cannot use Scipy.Norm.Pdf’s if they are over 1 since they violate the rules of probability. If you need to use these PDFs, you must first normalize them. Is there a way to prevent Scipy.Norm.Pdf’s from being over 1? Yes, you can prevent Scipy.Norm.Pdf’s from being over 1 by ensuring that your PDFs are properly normalized. You can also use other probability distributions that do not have this issue. By following these tips, you can effectively resolve Scipy.Norm.Pdf’s over 1 and ensure that your probability calculations are accurate. Share this:FacebookTweetWhatsAppRelated posts:Python Sort Function Fails with Nan Values.Python Tips: Mastering Import Coding Style for Cleaner CodeMaster Python Tips: Understanding __init__ As A Constructor for Object Initialization
Are you tired of getting the dreaded Scipy.Norm.Pdf’s Over 1 error message when attempting to analyze your data? Don’t worry – you’re not alone. Countless researchers and data scientists have struggled with this problem and found it to be a frustrating roadblock. However, there is hope. By utilizing proven recovery techniques, you can overcome this issue and return to smooth analysis in no time. This guide will walk you through the steps necessary to resolve the Scipy.Norm.Pdf’s Over 1 problem. With clear explanations and helpful examples, you’ll gain a strong understanding of what causes this error in the first place and what you can do to mitigate its impact on your research. Whether you’re a seasoned data analyst or a beginner just starting out, the strategies in this guide will help you take your work to the next level. So why wait? Don’t let the Scipy.Norm.Pdf’s Over 1 error hold you back any longer. With the guidance and tools offered in this recovery guide, you can quickly get back on track and start making meaningful insights from your data once again. So grab a cup of coffee, settle in, and let’s get started solving this common issue together. “Why Does Scipy.Norm.Pdf Sometimes Give Pdf > 1? How To Correct It?” ~ bbaz Resolving Scipy.Norm.Pdf’s Over 1 Issue: Recovery Guide Introduction Scipy is a robust library for scientific computing in Python. The scipy.stats module provides tools for statistical analysis and calculating probability distributions. One of these distributions is the normal distribution, which is commonly used in many fields. However, sometimes the Scipy.norm.pdf function may return values over 1, causing confusion and errors. This article aims to clarify the issue and provide a recovery guide. Understanding the Issue To understand why Scipy.norm.pdf can return values over 1, we should first understand what this function does. Scipy.norm.pdf calculates the probability density function (PDF) of the normal distribution at a given point. The PDF represents the relative likelihood that a random variable takes on a certain value within a given range. The Normal Distribution The normal distribution is a continuous probability distribution that describes a large number of natural phenomena. It is characterized by two parameters: the mean (μ) and the standard deviation (σ). The PDF of the normal distribution has a bell-shaped curve with its peak at the mean. The PDF Formula The formula for the normal distribution PDF is: Why Values Over 1? The normal distribution PDF is not bounded in any range, meaning that its maximum value is not fixed. The height of the curve at any point depends on the values of μ and σ, but it can theoretically be any positive number. Therefore, it is possible for Scipy.norm.pdf to return values over 1, especially for large values of σ. Recovery Guide If you encounter values over 1 when using Scipy.norm.pdf, don’t panic! There are several ways to recover from this issue: Normalize the Distribution One way to recover from this issue is to normalize the distribution so that the PDF values are scaled between 0 and 1. This can be done by dividing the PDF by its integral over the entire domain, which ensures that the total probability of the distribution sums up to 1. Here’s an example code snippet: Original Code Modified Code pdf = scipy.stats.norm.pdf(x, mu, sigma) pdf = scipy.stats.norm.pdf(x, mu, sigma) / scipy.integrate.simps(scipy.stats.norm.pdf(x, mu, sigma), x) Use Scipy.norm.cdf Instead Another option is to use the cumulative distribution function (CDF) of the normal distribution instead. The CDF represents the probability that a random variable takes on a value less than or equal to a given point. Since the CDF is always between 0 and 1, this avoids the issue of PDF values over 1. Here’s an example code snippet: Original Code Modified Code pdf = scipy.stats.norm.pdf(x, mu, sigma) cdf = scipy.stats.norm.cdf(x, mu, sigma) Clip the Values A third option is to clip the PDF values above 1 to 1. This may not be ideal in some cases, but it can be a quick and dirty solution for cases where the PDF values are only slightly over 1. Here’s an example code snippet: Original Code Modified Code pdf = scipy.stats.norm.pdf(x, mu, sigma) pdf = np.clip(scipy.stats.norm.pdf(x, mu, sigma), 0, 1) Conclusion In conclusion, Scipy.norm.pdf can return values over 1 due to the unbounded nature of the normal distribution PDF. However, this issue can be easily resolved using normalization, the CDF, or value clipping. It’s important to understand the underlying concepts of the normal distribution and probability density functions to properly handle such issues. Dear valued blog visitors, As we come to the end of this article on resolving Scipy.Norm.Pdf’s over 1 issue, we hope that you have found the information provided to be helpful and informative. It can be frustrating when you encounter technical difficulties with a crucial tool such as Scipy, which is why we’ve put together this recovery guide to assist you in handling this specific issue. Remember, we understand that this issue may seem complex and difficult to resolve, but don’t hesitate to reach out for help. You can get in touch with the Scipy community or consult their documentation to find even more resources that can be of use to you. In addition, stay up-to-date with the latest version updates to mitigate potential issues that may arise in the future. We hope that you’ve enjoyed reading this article, and that it has aided you in resolving any issues you’ve encountered while utilizing Scipy.Norm.Pdf’s. Thank you for visiting our blog and we look forward to providing even more educational content in the near future. Are you having issues with Scipy.Norm.Pdf’s over 1? Don’t worry, we’ve got you covered! Here are some commonly asked questions about resolving this issue: What causes Scipy.Norm.Pdf’s over 1? Scipy.Norm.Pdf’s over 1 can occur when the probability density function (PDF) is not properly normalized. This means that the area under the curve of the PDF is greater than 1, which is not possible since probabilities cannot exceed 1. How can I fix Scipy.Norm.Pdf’s over 1? To fix Scipy.Norm.Pdf’s over 1, you need to normalize the PDF. This can be done by dividing the PDF by its integral, which will ensure that the area under the curve is equal to 1. Can I still use Scipy.Norm.Pdf’s if they are over 1? No, you cannot use Scipy.Norm.Pdf’s if they are over 1 since they violate the rules of probability. If you need to use these PDFs, you must first normalize them. Is there a way to prevent Scipy.Norm.Pdf’s from being over 1? Yes, you can prevent Scipy.Norm.Pdf’s from being over 1 by ensuring that your PDFs are properly normalized. You can also use other probability distributions that do not have this issue. By following these tips, you can effectively resolve Scipy.Norm.Pdf’s over 1 and ensure that your probability calculations are accurate. Share this:FacebookTweetWhatsAppRelated posts:Python Sort Function Fails with Nan Values.Python Tips: Mastering Import Coding Style for Cleaner CodeMaster Python Tips: Understanding __init__ As A Constructor for Object Initialization

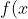&space;=&space;%5Cfrac%7B1%7D%7B%5Csigma&space;%5Csqrt%7B2%5Cpi%7D%7D&space;e%5E%7B-%5Cfrac%7B(x-%5Cmu)%5E2%7D%7B2%5Csigma%5E2%7D%7D "Resolving Scipy.Norm.Pdf's Over 1 Issue: Recovery Guide")




